Bahas Soal RAG
Yo halo para pembaca semua. Kalo kalian baca ini, disclaimer dulu sebelum jauh membaca dan menyesal. Ini akan jadi bacaan yang sedikit butuh effort untuk dipahami karena gw bakal bahas base konsep sampai jeroan matematika RAG secara mendalam. Bakal boring dan membingungkan, jadi skip saja kalau tidak tertarik. tapi kalau kalian masih bertahan, berarti kalian tertarik buat baca. Selamat membaca.
Btw, cerita dikit nih. Dulu waktu tugas akhir, gw udah membahas RAG dan cukup excited sama research nya. Tapi ya, waktu itu terburu-buru - deadline sidang, banyak hal lain yang harus diselesaiin, dan akhirnya research nya nggak sampai sedalem yang gue pengen. Jadi artikel ini sebenernya adalah kelanjutan dari obsesi dulu yang baru bisa dilanjutin sekarang. Menyempatkan diri buat riset lebih dalam dan menulis tulisan “ga jelas” di bawah ini yang semoga bisa jadi catatan bermanfaat atau setidaknya mediocre untuk siapa yang tertarik sama RAG.
Bayangkan dalam tiga tahun terakhir saja sudah ada lebih dari 1000 paper yang membahas RAG. Tren ini meledak karena RAG adalah solusi paling masuk akal buat mengatasi keterbatasan Large Language Model (LLM). Singkatnya, RAG atau Retrieval-Augmented Generation adalah cara kita kasih “buku panduan” berupa data eksternal ke AI sebelum dia menjawab pertanyaan kita. Jadi AI tidak cuma mengandalkan hafalan dari masa training (parametric memory), tapi dia juga punya akses ke memori luar (non-parametric memory) sebagai referensi.
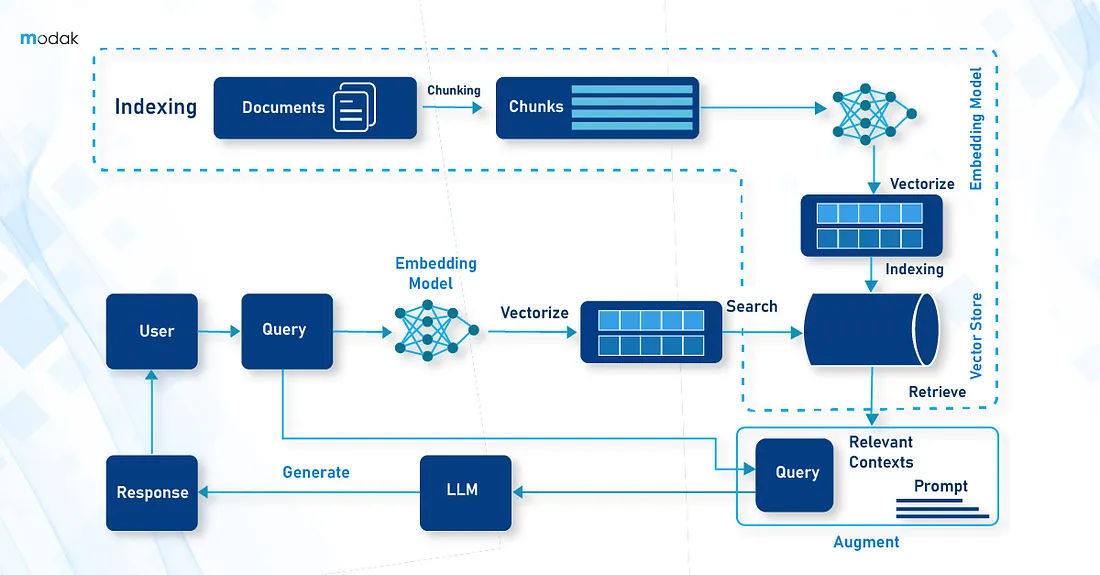
Kenapa Harus RAG? (Vanilla Recap)
LLM biasanya cuma pintar di data publik hasil training mereka. Masalah muncul saat kamu tanya soal data internal perusahaan atau kode privat yang tidak pernah dilihat si model saat fase pre-training. Dulu solusinya adalah fine-tuning atau melatih ulang model dengan data kamu. Tapi cara ini memerlukan infrastruktur mahal, skill khusus, dan ada risiko AI malah lupa kemampuan aslinya yang disebut catastrophic forgetting. Belum lagi masalah halusinasi di mana AI menjawab dengan sangat yakin padahal salah total.
RAG datang menyelamatkan dengan pendekatan non-parametric. Artinya kita tidak utak-atik jeroan atau bobot (weights) si AI yang sudah fix. Kita cuma nambahin modul pencarian (retrieval) di depannya untuk memperkaya query user dengan konteks spesifik sebelum dikirim ke LLM. Hasilnya AI jadi lebih jujur karena jawabannya “grounded” pada fakta, datanya selalu up-to-date tanpa perlu training ulang, dan jauh lebih hemat biaya operasional.
Dasar Teori: Entropy dan Kebingungan Model
Dalam membangun sistem RAG yang presisi, kita harus memahami metrik untuk mengukur ketidakpastian informasi menggunakan konsep Information Theory.
1. Shannon Entropy untuk Dokumen
Sebuah dokumen () dipandang berisi kumpulan konsep () yang probabilitasnya dipengaruhi oleh konteks (). Rumusnya adalah:
Sederhananya, mengukur tingkat ketidakteraturan data kamu. RAG bekerja maksimal pada dataset dengan Low Entropy, yaitu konten yang konsisten dan bermakna. Jika dokumen kamu berantakan (High Entropy), sistem tidak bisa menjamin informasi yang diambil berasal dari dokumen yang benar.
2. Conditional Entropy
Semakin banyak konsep () yang dimasukkan ke dalam konteks, model harus mengelola lebih banyak interdependensi, yang meningkatkan ketidakpastian. Rumus Conditional Entropy mengukur seberapa bingung LLM saat harus memilih jawaban () dari ruang kemungkinan () berdasarkan pertanyaan () dan konteks ():
Semakin banyak konsep tidak relevan atau “sampah” yang masuk ke context window, semakin tinggi nilai entropy ini, yang berujung pada halusinasi.
Anatomi Proses RAG
Menurut studi dari National Taiwan University, proses RAG melibatkan penyelarasan konseptual (Conceptual Alignment):
- Attention: Menggunakan self-attention untuk menyelaraskan konsep antara konteks dan pertanyaan.
- Conceptual Alignment: Saluran untuk mencocokkan konsep yang bisa dilakukan oleh LLM atau model term-based seperti BM25 (Robertson and Zaragoza, 2009).
- Generation: Memproduksi jawaban akhir berdasarkan konsep yang sudah selaras.
Secara formal, model RAG dapat dilihat sebagai model generatif variabel laten yang mendefinisikan distribusi probabilitas output () dengan melakukan marginalisasi terhadap dokumen yang diambil ():
Di sini, adalah distribusi output dari retriever, sedangkan adalah probabilitas kondisional generator untuk menghasilkan jawaban berdasarkan query dan dokumen tertentu.
Modul Utama: Retriever dan Generator
Retriever (Dense Passage Retrieval)
Retriever bertugas mengidentifikasi teks mana dalam korpus besar yang relevan dengan query user. Implementasi modern sering menggunakan DPR (Dense Passage Retrieval). DPR menggunakan bi-encoder: satu encoder untuk pertanyaan () dan satu untuk passage () yang memetakan teks ke dalam vektor d-dimensi dalam ruang yang sama. Relevansi diukur melalui skor kemiripan, biasanya menggunakan dot product:
Model ini dilatih dengan Contrastive Loss untuk memastikan pasangan pertanyaan-jawaban yang benar memiliki jarak vektor yang dekat, sementara pasangan yang salah menjauh. Rumus loss fungsinya adalah:
Generator (Conditional Seq2Seq Model)
Generator biasanya berupa model bahasa sequence-to-sequence (seperti BART atau T5) yang menghasilkan teks akhir berdasarkan query dan dokumen hasil retrieval (). Generator mengkondisikan diri pada bukti eksternal untuk mengurangi halusinasi dibandingkan hanya mengandalkan pengetahuan internal. Proses integrasi ini memastikan jawaban yang dihasilkan tidak hanya fasih secara linguistik, tetapi juga akurat secara faktual.
Penutup
Dah ah capek, udah ngebas RAG mulai dari konsep dasar sampai rumus-rumus yang bikin kepala ku ngebul, sebenarnya masih banyak yang mau ku tulis, tapi malas nulis. Semoga sekarang kalian punya gambaran yang lebih jelas tentang gimana RAG bekerja di balik layar.
Real talk, RAG adalah game-changer banget untuk LLM. Daripada ribet-ribet fine-tuning atau training model dari nol dengan data pribadi, kita tinggal tambahin retrieval system yang cerdas. Hasilnya lebih murah, lebih cepat, dan yang paling penting - jawabannya jadi lebih tepat dan nggak asal-asalan.
Thx sudah bertahan sampe akhir :). Semoga tulisan “ga jelas” ini bermanfaat dan bikin kalian makin jago, ah ngga juga paling cuma namabah pusing. cao!!